对象的优化
一、拷贝构造、赋值运算符重载的相关知识
一、拷贝构造、赋值运算符重载的相关知识
1、操作系统要干啥?哪些操作/任务不属于操作系统的管理范畴?
2、工具使用
阅读源码工具:understannd
源码文档自动生成工具:doxygen
虚拟运行环境:qemu
Lab0
1、了解汇编
1 | int count = 1; |
3、掌握指针和类型转换相关的C编程
实验源码如下
1 |
|
自己根据输出即可推出来是怎么做的。注意,gintr等于0xee0000010002中,最高16位全部等于0没有展示出来。而%x只能展示32位,所以intr的输出结果为:0x10002。
硬盘主引导扇区(Master Boot Record,MBR)是位于硬盘第一个扇区(通常是逻辑地址0号扇区)的512字节的数据结构,用于引导计算机操作系统。一个符合规范的硬盘主引导扇区应该包含以下几个特征:
引导代码(Boot Code): 前446个字节用于存储引导代码,这是引导加载程序(Boot Loader)的代码,负责加载操作系统。这段代码必须是有效的汇编代码,能够启动计算机。
分区表(Partition Table): 接下来的64字节用于存储分区表,每个分区表项占16字节。一个硬盘可以分为最多4个主分区,每个分区表项描述一个分区的起始位置、大小和分区类型等信息。
签名字节(Signature): 最后的两个字节(0x55AA)是MBR的签名,标志这个扇区是有效的MBR扇区。这个签名是个小端字节序的16位值,它告诉操作系统这个扇区包含了引导信息,是一个有效的MBR。
总结起来,一个被系统认为是符合规范的硬盘主引导扇区应该包含引导代码、分区表和签名字节。这些特征是为了确保引导加载程序可以正确地读取分区信息,从而启动操作系统。如果这些特征中的任何一个缺失或损坏,可能导致系统无法正确引导。
引导扇区代码(tools/sign.c)
1 |
|
这里因为做项目的需要,我先写下8.6节有关有限状态机的内容
这一节我们介绍逻辑单元内部的一种高效编程方法:有限状态机。有的应用层协议头部包含数据包类型字段,每种类型可以映射为逻辑单元的一种执行状态,服务器可以根据它来编写相应的处理逻辑。
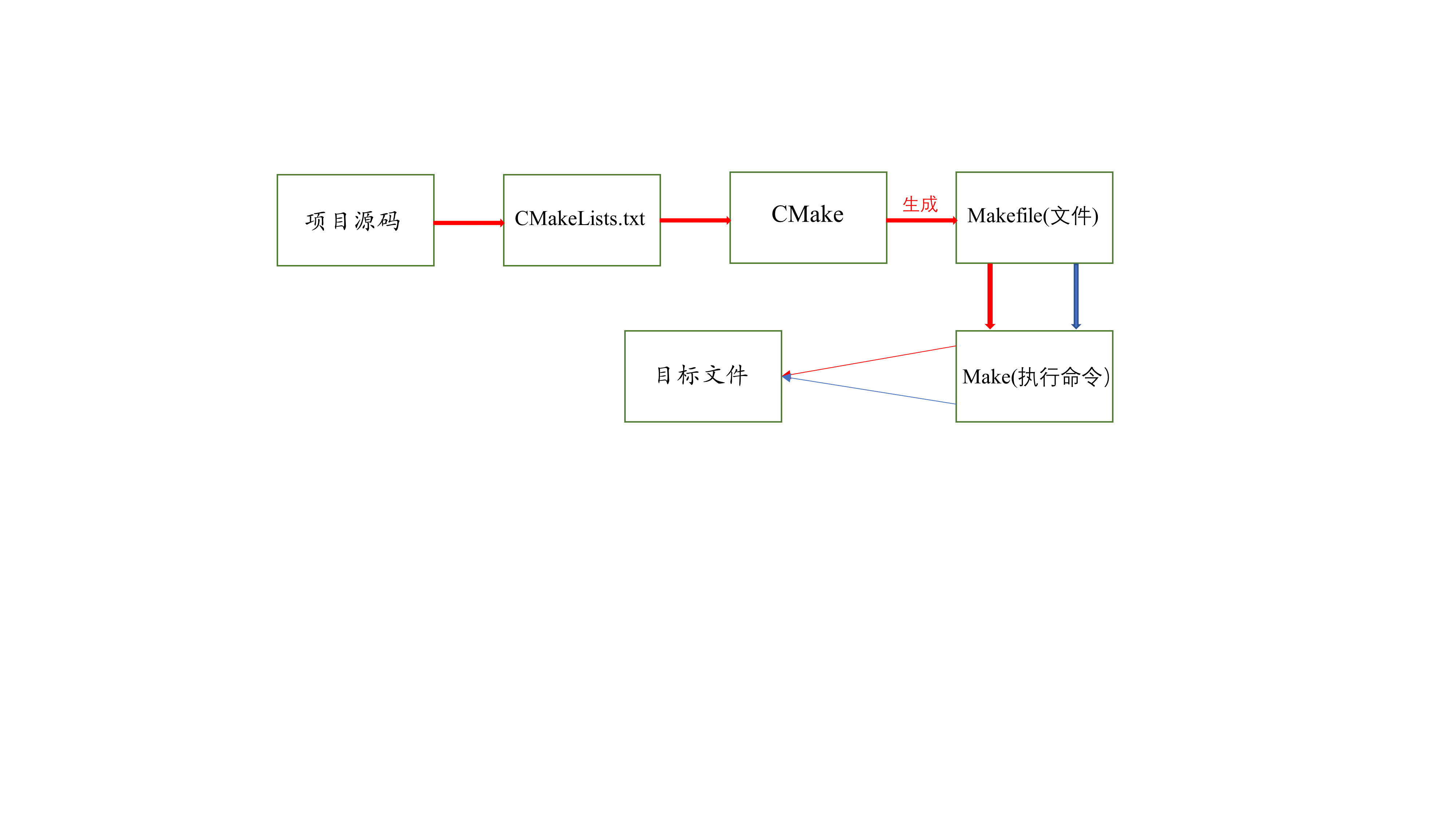
这里画一个图直接直接展示一下CMake和Makefile的使用过程
1 | g++ *.cpp -o app //直接编译 |
使用#注释
块注释#[[ ]]
camke_minimum_required:指定使用的cmake的最低版本
project:定义工程名称
add_executable:定义工程会生成一个可执行程序 add_executable(可执行程序名称 源文件名称(空格或者分号隔离源文件))
cmake CMakeLists.txt:文件所在路径
1 | cmake_minimum_required(VERSION 3.15) |
生成了很多其他文件,我们可以把这些临时文件放在一个文件夹里,一般为build文件夹。创建build文件后,cd进build文件,执行camke ..,则cmake执行后生成的文件都放在了build文件夹里。
set的使用set是为了简化add_executable(app, add.cpp div.cpp mult.cpp main.cpp sub.cpp)的编写,要不然这样和直接编译感觉没啥区别。set给一个变量赋值都是字符串类型,这些文件的名字会作为一个字符串存在变量里。
1 | # set指令的语法是: |
取变量值必须以这种方式。
1 | # "$ + {变量名}" |
还可以通过set设置使用C++的标准(C++11,C++17)。
1 | 正常编译选定c++标准 |
1 | # 使用camke指定c++标准,对应有一个宏叫做DCMAKE_Cxx_STANDARD |
set还可以指定输出路径,建议使用绝对路径,如果这个路径中的子目录不存在,会自动生成,无需自己手动创建。
1 | # 在CMake中指定可执行程序输出的路径,也对应一个宏,叫做EXECUTABLE_OUTPUT_PATH,它的值还是通过set命令设置 |
我们可以看到我们上面所讲的使用set并没有解决要将所有源文件名字写出来的本质问题。为了解决这个问题,这里我们讲一下通过搜索某个目录下的文件来引入源文件的方法。CMake给我们提供了两种方法来搜索文件,aux_source_directory命令或者file命令。
在CMake中使用aux_source_directory命令可以查找某个路径下的所有源文件。
1 | # 命令格式 |
通过file命令来搜索出所有需要的源文件
1 | # 命令格式 |
在编译项目源文件的时候,很多时候都需要将源文件对应的头文件路径指定出来,这样才能保证在编译过程中编译器能找到这些头文件。在CMake里搜索头文件的命令也很简单
1 | include_directories(headpath) |
有些时候我们编写的源代码并不需要将他们编译生成可执行程序,而是生成一些静态库或动态库提供给第三方使用,下面来讲解在cmake中生成这两类库文件的方法。
1 | # 在cmake中,如果要制作静态库,需要使用的命令如下: |
1 | cmake_minimum_required(VERSION 3.0) |
对于生成的库文件来说和可执行程序一样都可以指定输出路径。这里使用LIBRARY_OUTPUT_PATH宏,这个宏对应静态库文件和动态库文件都适用。
1 | cmake_minimum_required(VERSION 3.0) |
在编写程序的过程中,可能会用到一些系统提供的动态库或者自己制作出的动态库或者静态库文件,cmake中也为我们提供了相关的加载动态库的命令。
1 | src |
现在我们把上面src目录中的add.cpp、div.cpp、mult.cpp、sub.cpp编译成一个静态库文件libcalc.a。
1 | 测试目录结构 |
在cmake中,链接静态库的命令如下:
1 | link_libraries(<static lib> [<static lib>...]) |
如果该静态库不是系统提供的(自己制作或者使用第三方提供的静态库)可能出现静态库找不到的情况,此时可以将静态库的路径也指定出来:
1 | link_directories(<lib path>) |
这样,修改之后的CMakeLists.txt文件内容如下:
1 | cmake_minimum_required(VERSION 3.0) |
target不知道这个符号是来自它链接的多个库中的哪一个库,它只知道有这么一个库。
FATAL_ERROR:CMake 错误, 终止所有处理过程(CMake在生成”message to display”这条消息之后就不在执行了,直接中断)
CMake在底层管理的时候会将子字符串通过分号隔开,但通过message打印变量值的时候,看不到这个分号。这个分号有助于cmake进行字符串删除操作。只能删除组成变量的子串。比如一开始SRC=“A123”,后来apeend了“456”, “789”,如果没有分号,你可能可以删除”345”,但有了分号后,就删除不了了,你只能删除组成SRC的完整的子串,比如”A123”, “456”等。
注意,存储列表长度的output variable依旧是一个字符串类型。
DAY1使用指令创建数据库:CREATE DATABASE zcl_db01;
删除数据库指令:DROP DATABASE zcl_db01;
创建一个使用utf8字符集的zcl_db02数据库:CREATE DATABASE zcl_db02 CHARACTER SET utf8
创建一个使用utf8字符集,并带校对规则的zcl_db03数据库:CREATE DATABASE zcl_db03 CHARACTER SET utf8 COLLATE utf8_bin utf8_bin区分大小写,utf8_general_ci不区分大小写
1 | #查看当前数据库服务器中的所有数据库 |
1 | #备份数据库 |
DAY21 | # 创建表 |
1 | # Mysql列类型就是Mysql的数据类型 |
在满足需求的情况下,尽量选择占用空间小的类型
1 | CREATE TABLE t3( |
1 | # BIT(M), M在1-64。显示按照bit。 |
1 | # DECIMAL[M, D] |
1 | # char(4) 这个4表示字符数(最大255),不是字节数,不管是中文还是英文都是放四个,按字符计算,定长,即使你插入'aa',也会占用分配的4个字符的空间 |
1 | # 日期类型 date datetime timestamp |
1 | CREATE TABLE 'emp'( |
1 | # 使用INSERT语句向表中插入数据 |
1 | -- 演示update语句 |
1 | -- 演示delete语句 |
1 | -- select指定查询哪些列的数据 |
1 |
|
socket地址TCP/IP协议族有sockaddr_in和sockaddr_in6两个专用socket地址结构体,他们分别用于IPv4和IPv6,这里我只介绍sockaddr_in。
1 | struct sockaddr_in{ |
注意:所有专用socket地址类型的变量在实际使用时都需要转换为通用socket地址类型sockaddr(强制转换即可),因为所有socket编程接口使用的地址参数的类型都是sockaddr。
IP地址转换函数1 |
|
1 |
|
socket系统调用成功时返回一个socket文件描述符,失败返回-1并设置errno
创建socket时,我们给它指定了地址族,但是并未指定使用该地址族中的哪个具体socket地址。将一个socket与socket地址绑定称为给socket命名。在服务器程序中,我们通常需要命名socket,因为只有命名后客户端才知道该如何连接它。客户端通常不需要命名socket,而是采用匿名方式,也就是使用操作系统自动分配的socket地址。
1 |
|
socket被命名之后,还不能立即接收客户端连接,我们需要使用如下系统调用来创建一个监听队列以存放待处理的客户连接
1 |
|
下面我们编写一个程序测试一下
1 |
|
这个命令组合使用了两个命令:netstat 和
grep,并通过管道(|)将第一个命令的输出作为第二个命令的输入。我会为你逐步解释它:
netstat -nt:
netstat:
这是一个命令行工具,用于显示网络状态,包括网络连接、路由表、接口统计等。-n:
表示以数字形式显示地址和端口号,而不是尝试解析它们的名称。-t: 仅显示TCP连接。因此,netstat -nt
的输出会列出系统上所有活动的TCP连接,同时显示它们的源和目标IP地址以及端口号,并直接显示数字而不进行名称解析。
|:grep 8000:
grep:
是一个强大的文本搜索工具,用于搜索匹配的字符串。8000: 是你想在 netstat
的输出中搜索的字符串。netstat 的输出中筛选出所有包含 “8000”
的行,这通常意味着你正在查找与端口 8000
相关的所有活动连接。综上所述,netstat -nt | grep 8000 会显示所有在端口
8000 上的活动TCP连接。
代码:接受一个异常的连接
1 |
|
1、第一次运行报错,undefined reference to main,这种情况一般有三种可能:
2、accept函数是阻塞的,上述代码即服务器端运行的时候,会阻塞在accept处,一旦客户端请求建立连接,服务器立马终止程序。注意accept只是从listen监听队列中取出连接,它不会理会客户端处于什么状态。
3、一直在思考select/poll/epoll这些有什么用。首先因为listen是有监听队列的,劣势就在于只能一个个处理,并且同时接入的连接数有限。比如队列长度为5,处理完一个,再建立下一个连接,这样如果某一个连接处理很长时间一直阻塞在那里,就导致后面的新请求连接建立超时。很直观的想法是fork新进程或者创建新线程来处理新连接,每来一个连接我就创建一个来跟他对接。这样资源消耗太大。因此就有了select/poll/epoll,先把连接建立起来并放进文件描述符,最后从这里面寻找哪些发生了可读可写事件,也避免了因为读写事件造成的阻塞(没有数据到来就阻塞了)。
有关C++内存管理问题总结如下
C++中堆和栈的区别是什么C++的内存分区:堆区、栈区、data区、bss段、代码段。数据data区存放的是静态变量和初始化的全局变量,bss段存放的是未初始化的全局变量。RAII?为什么它在C++中很重要RAII是一种编程思想和设计模式,核心思想是:将资源的获取与对象的初始化捆绑在一起,将资源的释放与对象的销毁捆绑在一起。这样,资源管理就与对象的生命周期紧密关联。
1 |
|
new和delete,与malloc和free的区别属性的区别
new/delete:这两个是C++中的关键字;
malloc/free:这两个是库函数;
使用上的区别
malloc:申请空间需要显式填入申请内存的大小;
new:无需显式填入申请内存的大小,new会根据new的类型分配内存;
返回类型的区别
new操作符内存分配成功,返回的是对象类型的指针,类型严格与对象匹配,无需进行类型转换,故new是符合类型安全性的操作符。
malloc内存分配成功返回的是void*指针,需要通过强制类型转换,转换成我们需要的类型。
所以C++中new比malloc安全可靠。
分配失败的区别
malloc分配失败会返回NULL,我们可以通过判断返回值是否是NULL得知是否分配成功。
new分配失败会抛出bad_alloc异常。
扩张内存的区别
malloc有内存扩张机制(通过realloc实现)。
new没有扩张内存机制。
C++推荐使用智能指针,如shared_ptr和unique_ptrunique_ptr,当它超出作用域或者被重新分配时,它指向的对象会被删除。对于shared_ptr,当它的引用计数为0时,它指向的对象会被删除。unique_ptr和shared_ptr可以减少悬挂指针的风险,因为他们确保在没有引用的时候释放资源。shared_ptr中的引用计数机制是如何工作的吗指针重新赋值
1 | int *p = new int(); |
错误的内存释放
假设有一个指针p指向10字节的内存,该内存的第三个字节np又指向某个动态分配的内存,
如果此时你直接delete(p),则会导致np指向的内存无法释放。
返回值的不正确处理
1 | int *f(){ |
关于内存泄露可以使用工具:Valgrind。
话不多说,直接上代码
1 |
|
问题
构造析构为什么要私有
解答:
在单例模式中,构造函数和析构函数被设置为私有的原因是为了确保满足单例模式的核心要求:系统中某个类只能存在一个实例。
通过将构造函数和析构函数设为私有,我们可以确保以下几点:
外部无法实例化:由于构造函数是私有的,这意味着不能在类的外部直接创建该类的实例。这确保了实例的创建只能通过单例类提供的某些特定方法(如getInstance)来完成,从而控制实例的数量。
禁止复制:单例模式要确保只有一个实例存在,所以我们不希望该类的对象被复制。将构造函数设为私有可以防止复制构造,但为了进一步确保不被复制,我们通常还需要禁止拷贝构造函数和拷贝赋值操作符(通过= delete)。
外部无法销毁:将析构函数设为私有可以确保外部代码无法直接删除单例对象。通常,单例对象在程序结束时自动销毁,或者单例类提供了一个专门的方法来手动销毁它。
继承控制:由于构造函数和析构函数是私有的,这也意味着这个类不能被继承(因为派生类的构造函数需要调用基类的构造函数)。
综上所述,将构造函数和析构函数设为私有是为了确保满足单例模式的设计原则,即系统中该类只有一个实例,并提供对该实例的全局访问点。
本篇文章主要参考如下文章,主要是对代码做一个较为详尽的解释
参考链接:https://blog.csdn.net/qq_46495964/article/details/122952567
前言:
日志系统在程序运行中有着非常大的作用,用于记录程序的运行情况,在程序出错后查看日志,方便地定位出错的大概范围。在设计日志系统之前,先考虑一下日志需要输出什么信息呢?什么信息才是有用的信息,都知道写日志是一种对文件的io操作,所以尽可能避免输出没用的信息。
有用的信息:关键变量的值、运行的位置(哪个文件、哪个函数、哪一行)、时间、线程号、进程号等等。
日志的级别
在测试、调试、交付等场景需要输出不同的级别日志。
1 | //常见的日志级别 |
日志的输出地
日志输出的地方可能不同,终端、控制台、UI界面、文件等等都有。
1 | enum LOGTARGET |
日志的作用域
日志做到什么时候都可以输出,可作用于全程序文件,考虑到多线程情况下,必须保证日志的输出需要得到线程安全的保障,所以需要一个全局且唯一的日志器。使用设计模式中的单例模式—–日志器
Logger.h
1 | 这是一个基本的线程安全日志系统的头文件,其目的是为应用程序提供日志功能。以下是对这个头文件的详细解释: |
1 | /** |
Logger.cpp
1 | 这是日志类的实现文件`Logger.cpp`。它对`Logger.h`中定义的函数进行了具体的实现。我将分步解释这个文件的内容: |
1 | /** |
Stop方法: 设置exit_标志为true。 通过条件变量通知日志线程。 等待日志线程结束
请问这里为什么需要通知日志线程
解答:在Logger类的实现中,日志线程的工作是从队列中获取日志消息并将其写入文件。为了实现这个功能,它在队列为空时通过cv_.wait(guard)进入休眠状态,等待新的日志消息的到来。
当你调用Stop方法时,你希望日志线程能够尽快结束。但有一种情况需要考虑:当Stop被调用时,队列可能仍然是空的,这意味着日志线程可能处于cv_.wait(guard)的休眠状态。
在这种情况下,即使你设置了exit_标志为true,日志线程仍然不会醒来检查这个标志,因为它正在等待新的日志消息到来。
为了确保日志线程能够醒来、检查exit_标志并正确地退出,你需要在Stop方法中通过cv_.notify_one()通知日志线程。这样,日志线程将被唤醒,然后它可以检查exit_标志,并根据该标志的值决定是否退出。
总之,通知日志线程是为了确保它可以从cv_.wait(guard)中醒来,然后检查退出条件并安全地退出。
这个程序没有设计线程来将新的日志信息加入队列吗
从提供的代码来看,日志系统中只设计了一个专门的日志线程(在Logger::Start()方法中启动),其任务是从队列中提取日志消息并将其写入文件。此外,并没有为添加新日志消息到队列专门设计线程。
当你希望写入日志时,只需在你的主程序或任何其他线程中调用LogInfo(),
LogWarning(), 或
LogError()这样的宏。这些宏内部会调用Logger::AddToQueue(),该方法将日志消息格式化并加入到队列中。这种设计的优点是简单且高效,因为它允许多个线程在运行时无缝地向日志系统添加消息,而无需额外的线程。
但值得注意的是,Logger::AddToQueue()使用了互斥锁mutex_来保证多个线程同时向队列添加消息时的线程安全。这意味着,即使多个线程同时调用日志宏,Logger::AddToQueue()中的代码仍然是线程安全的。
总的来说,这个日志系统的设计考虑到了多线程环境,允许多个线程同时添加日志消息,但它并没有专门设置一个线程来完成这项任务,而是允许主程序或其他任何线程来直接调用添加日志的宏。
自己的话:你自己程序在运行的时候是不是有多个线程,这些线程就是负责啥时候要调用LogInfo(),
LogWarning(), 或
LogError()这样的宏。所以当然不需要额外的线程来操作加入队列操作,只需要一个带锁函数即可。